


干货分享 | 政务数据资源中心(框架)建设方案
政务数据资源中心是逻辑上各种原始数据的集合,包括原始层和标准层两个部分。
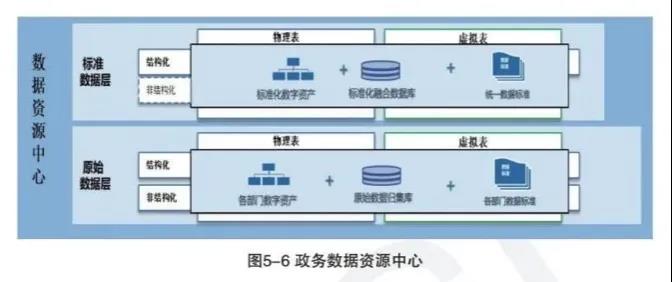
原始数据层是逻辑上各种原始数据的集合,除了“原始”这一特征外,还具有“海量”和“多样”(包含结构化、非结构化数据)的特征。数据资源中心保留数据的原格式,原则上不对数据进行清洗、加工,但对出现数据资产多源异构的场景需要整合处理,并进行数据资产注册。
标准数据层是在原始数据层的基础上,通过政务对象数据识别形成国家级统一数据标准,构建标准化融合数据库。这层的标准数据会进行通用规则的清洗、加工,在对象数据的识别和治理下,形成全局各类逻辑实体的关联关系,可以同时形成一个大宽表,并进行数据资产的注册,形成标准化数据资产。
01 基于入湖标准治理的原始层构建
一、政务数据入湖标准
数据入湖是数据协同治理消费的基础,需要严格满足入湖的6项标准,包括明确数据所有者、发布数据标准、定义数据共享属性、明确数据源、数据质量评估、元数据注册。
通过这6项标准保证入湖的数据都有明确的业务责任人,各项数据都可理解,同时都能在相应的信息安全保证下进行消费。
1.明确数据所有者
数据所有者由数据产生对应的流程所有者担任,是所辖数据端到端管理的责任人,负责对入湖的数据定义数据标准和共享属性,承接数据消费中的数据质量问题,并制定数据管理工作路标,持续提升数据质量。
2.发布数据标准入湖
数据要有相应的业务数据标准。业务数据标准描述政府层面需共同遵守的“属性层”数据含义和业务规则,是政府层面对某个数据的共同理解,这些理解一旦明确并发布,就需要作为标准在企业内被共同遵守。
3.认证数据源
通过认证数据源,能够确保数据从正确的数据源头入湖。认证数据源需遵循政务数据源管理的要求,数据源一般是指业务上首次正式发布某项数据的应用系统,并经过数据管理部门。
认证过的数据源作为唯一数据源头被数据资源中心调用。当承载数据源的应用系统出现合并、分拆、下线情况时,需及时对数据源进行失效,并启动新数据源认证。
4.明确数据共享属性
定义数据共享属性是数据入湖的必要条件,为了确保数据资源中心中的数据能充分的共享,入湖的数据必须要定义数据共享属性。
责任主体是数据所有者,数据管家有责任审视入湖数据共享属性的完整性。
5.数据质量评估
数据质量是数据消费结果的保证,数据入湖不需要对数据进行清洗, 提升数据质量,但需要对数据质量进行评估,让数据消费的人员了解数据的质量情况,并了解消费该数据的质量风险。
同时,数据所有者和数据管家可以根据数据质量评估的情况,推动源头数据质量的提升,满足数据质量的消费要求。
6.元数据注册
元数据注册是指将入湖数据的业务元数据和技术元数据进行关联,包括逻辑实体与物理表的对应关系,及业务属性和表字段的对应关系。
通过联接业务元数据和技术元数据的关系,能够支撑数据消费人员通过业务语义快速的搜索到数据资源中心中的数据,降低数据资源中心中数据消费的门槛,能让更多的业务分析人员能理解和消费数据。
二、政务数据入湖方式
数据入湖以逻辑数据实体为粒度进行入湖,逻辑数据实体在首次入湖时应该考虑信息的完整性,原则上一个逻辑数据实体的所有属性应该一次进湖,避免一个逻辑实体多次入湖,增加入湖工作量。
数据入湖的方式主要有物理入湖和虚拟入湖两种,根据数据消费的场景和需求,一个逻辑实体可以有不同的入湖方式。两种入湖方式相互协同,共同满足数据联接和用户数据消费需求,数据管家有责任根据消费场景的不同,提供相应方式的入湖数据。
物理入湖指将原始数据复制到数据资源中心中,包括批量处理、数据复制同步、消息和流集成等方式。
虚拟入湖指原始数据不在数据资源中心中进行物理存储,而是通过建立对应虚拟表的集成方式实现入湖,实时性强,一般面向小数据量应用, 大批量的数据操作可能影响源系统。
数据入湖可以由数据资源中心主动从数据源通过PULL(拉)的方式入湖,也可以由数据源主动PUSH(推)的方式入湖。数据复制同步、数据虚拟化、以及传统数据仓库技术(ETL)批量集成都是属于数据资源中心主动拉的方式。流集成、消息集成属于主动推送的方式。
在特定批量集成场景下,数据会以CSV、XML等格式,通过文件传输协议(FTP)推送给数据资源中心。

1.结构化数据入湖
结构化数据是指由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
触发结构化数据入湖的场景有两种:一是政务数据管理组织基于业务主动规划、统筹数据入湖;二是响应数据消费方需求实施数据入湖。
结构化数据入湖过程包括:数据入湖需求分析及管理、检查数据入湖条件和评估入湖标准、实施数据入湖、注册元数据。
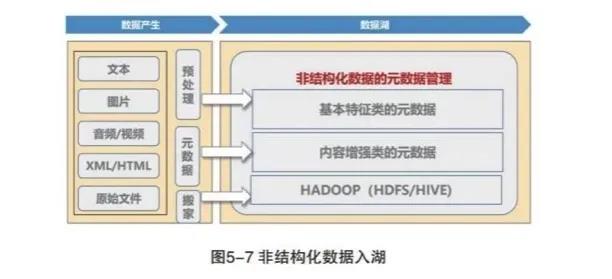
2.非结构化数据入湖
非结构化数据是指包括无格式文本、各类格式文档、图像、音频、视频等多样异构的格式文件,较之结构化数据更难对其标准化和理解。相较于结构化数据,非结构化数据管理不仅包括文件本身,也包括对文件的描述属性,也就是非结构化的元数据信息。
这些元数据信息包括文件对象的标题、格式等基本特征定义,还包括对数据内容的客观理解信息,如:标签、相似性检索、相似性连接等。这些元数据信息会便于用户对非结构化数据的搜索和消费。
非结构化数据入湖包括对非结构数据的基本特征元数据、文件解析内容、文件关系和原始文件入湖,其中基本特征元数据是非结构化数据入湖的必选内容,后面三项内容根据分析诉求可以选择入湖和延后入湖。
三、政务数据资源中心原始层的建设
政务数据原始层也是贴源数据层,是逻辑上各种原始数据的集合。各个部门会在数据资源中心中形成各自的部门的数据资产和原始数据归集库。
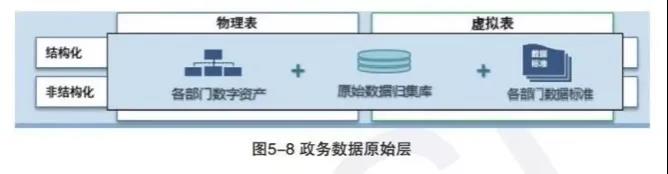
数据资源中心原始层保留数据的原格式,原则上不对数据进行清洗、加工。满足数据入湖标准的数据从中心前置节点或其它数据源完整的拷贝,保障大数据平台的数据和外部数据源数据的一致性。
原始层数据在模型上采取贴源设计,偏向于维持源系统数据组织的原貌形态,基本上不会考虑信息要素的删减,保持与源系统数据同样的数据结构。数据按照抽取的频率和增全量进行存储,每个频率单独保存一个表文件,能满足后续其他层次的需求即可。
归集贴源层存储上游源系统的明细数据,但不对数据进行整合处理,尽量保持业务数据原貌。
核心分为两个步骤:
第一步,将外部数据加载到数据资源中心的临时缓冲区,转换数据的形态,将转换后的数据纳入数据资源中心管理。
第二步,原始层保留源系统的全量历史数据,供后续数据深化加工使用,避免频繁访问各厅局委办的原始数据。
02 基于政务对象数据治理的标准层构建
一、政务对象数据
政务对象数据是指有共享性的基础数据,可以在政府各部门之间、政府与社会个人、单位之间内被重复使用的。比如,自然人的对象数据是指每个自然人的基本特性描述,如证件号码、姓名等,在每个人的生命周期中基本不会发生变化。
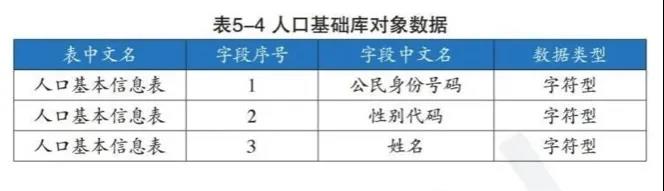
人口基础信息库对象数据包括如下内容:
政务对象数据治理以对象数据生命周期管理为核心,基于对象数据生命周期各个环节建立对象数据标准,以数据标准为依据搭建数据质量管理体系。
二、政务数据标准层的构建
政务数据标准层的构建是基于政务对象数据实现数据的标准化融合。建立一个统一、规范、标准化、涵盖各委办局信息系统数据,促进跨部门、跨层级数据互认与共享。

数据项在表结构层面进行归一和融合,同时,对于非结构化数据则进行文件解析和特征信息提取,并和上述结构化数据进行关联融合。
标准化数据库的设计和建设符合国家级统一数据标准和技术规范, 符合国家相关管理规范要求。
以人口基础信息资源库为例,依托于政务数据服务共享交换,以公安人口数据为基础,逐步融合卫计委、民政厅、人社厅、教育厅等部门的相关信息资源,重点建设和整合公安户籍信息、人口普查信息、公务员信息、社会保障信息和人事关系信息等信息资源,扩展健康、收入、婚姻、社保、救助、贫困、残疾、流动、死亡等信息,逐渐丰富人口基础信息资源条目,构建统一的、可共享的人口基础共享信息库。

对于结构化数据的标准化融合,遵循“一数一源”的原则对来自于多个部门的重复数据表和通过对象数据识别来关联多个数据源,构建人口库,实现人口信息的交换、处理、存储、更新、服务为一体的运行、管理、共享体系。为政府相关部门的业务应用、跨部门业务应用和宏观决策等提供基础数据支持与服务。
1.数据来源
以公安核实的实有人口信息为基础,覆盖本级政府行政区人口的基本信息、扩充信息,并且根据需要可以及时追加基础信息。接入公安、卫计、教育、民政、人社、住建等单位扩展信息,建立以公民身份证号码为唯一代码的实有人口库,实现以人口档案管理为基本,延伸到人口健康、社保、教育等关联信息。
人口基础信息资源库按照信息来源和信息归属划分,包括:劳动就业信息、社会保险信息、教育信息、卫生健康信息、民政信息、住房公积金信息、住房信息、税务信息、单位信息、申报信息等。根据不同信息资源类别,提供数据库表结构设计。
2.数据管理
数据管理根据建设人口基础数据库主题库所需的支撑模块和接口,包括用户管理、权限管理、用户组织机构管理、编目管理、消息中心、日志管理等功能。
能够维护人口库的基本内容构成可细化到字段级,并可维护每个字段从哪个信息资源中的某个指标获取,如有多个来源,需要提前确定数据协商计算规则。
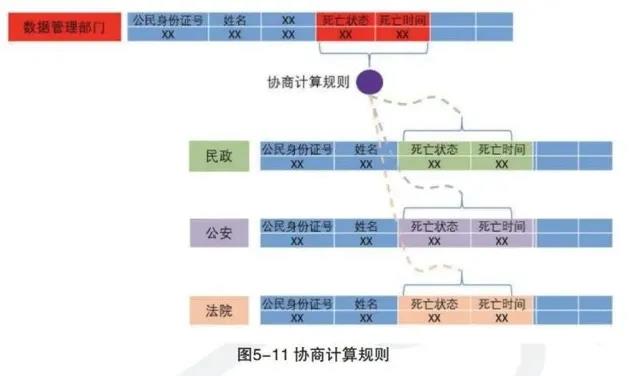
如上图,死亡数据在业务上有多个来源部门,如民政、公安、法院等,但数据管理部门在归集到自然人死亡相关数据时,需要组织多个数据源部门对数据最终状态的确定,制定协商计算规则,以计算规则确认数据最终状态。
3.数据集成
主要包括以下两方面内容:
数据清洗:照标准规范,针对数据本身属性错误的数据进行过滤,通过过滤规则,即可将这类错误数据过滤。通过数据清洗功能,为数据比对提供干净、准确的数据环境。
数据比对:将同一属性但来自不同数据源的数据,通过制定的比对规则进行比对。数据比对一致的,认定为准确;数据比对不一致的,认定为错误,反馈到相关部门进行核查。
4.数据更新机制
以人口库为例,人口库中的核心基础信息反映人口的基本属性,更新频率较低;扩展信息反映人口在不同阶段的状态属性,更新频率相对较大。
基础信息更新要求:由牵头部门公安人工核对后增量更新。其他部门无权进行更新、如果发现基础信息有误的,提交给牵头部门进行人工处理后增量更新。扩展信息更新要求需根据扩展信息设定的更新频率按谁主管谁负责增量更新。
本文节选自:《政务数据开发利用研究报告(2021版)》